关于Web,你可能不知道的……
Web,全称为 World Wide Web,是 Internet 上最重要和最为人们所熟知的应用之一。Web 是指 Internet 上所有基于 http 协议的 html 网页、图像、音频、视频等内容的集合。虽然 Web 可能早已成你每天日常生活的一部分,但相信你对 Web 背后的秘密仍然很感兴趣。本文向大家展示了关于 Web 的一些通常不为人所知而又有趣的细节。
虽然Internet(包括其前身ARPANET等)的历史比Web要长的多,但直到 Tim Berners-Lee 爵士于1989年设计出Web并在1991年开始实际运行之后,Internet才逐渐大众化并开始流行。自1995年开始,Web占据了整个 Internet的大部分流量,而成为Internet上最重要的一项应用(注意不是“之一”)。
这种影响一直延续到今天:在日常生活中,我们一般甚至不 区分“Internet”和“Web”,而“上网”这个词在很多情况下指的就是浏览Web。Web在流量上的主导地位自2000年起受到以napster为始祖的P2P的挑战。相比Web来说,P2P在大型文件的传输上具有很大优势,因此虽然从广度来说Web仍然是主导,但在流量上自2002年起被P2P应用超过。下图显示了自1993年到2004年Internet上重要协议的流量变化。
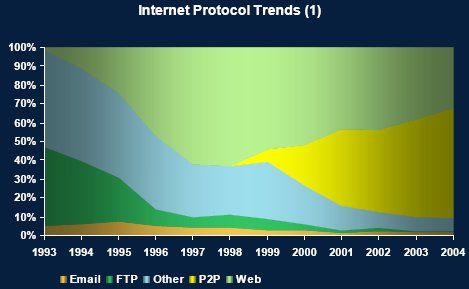
但这种状况在2007年发生了逆转。随着网络带宽的增加,以 YouTube 为首的在线视频网站开始流行,使得Web的流量迅速增长并重新超过了P2P流量,尽管这个“优势”很微弱。总结一下,仅从流量的角度看,目前的Internet可以说是Web和P2P各占半边天,而其余应用所占的比重是越来越小。关于Web和P2P流量更详细的分析可以参考这篇文章。
Web的规模定义为Web上包含的有效网页的数量。Google最近宣称已经索引了1,000,000,000,000个网页, 不过Google显然不敢宣称已经索引了Web上全部或绝大部分的网页,可以预计,Web的规模已经远远超过了上面这个数值。顺便提一句,“有效网页的数 量”严格来说其实是个伪命题,因为:1. 很多网站在被请求了不存在的页面时会返回一个友好的提示而非404错误(可以测试url:http://live.aulddays.com/ 后面跟上任意的文件名),理论上说它们仍然是“有效”的网页;2. 很多网页可以根据输入参数的不同而返回不同的结果(Google目前正着手解决的 Deep web 就是属于这种情况)。从这个意义上说,说Web的规模是无穷大的…
退而求其次,我们可以来估计一下有多少网页是Google没有索引到的:假设我们知道了两个不同的搜索引擎 A 和 B,它们索引的网页数量分别是 s(A) 和 s(B),A&B为两个搜索引擎的交集,那么根据容斥原理,所有被它们(中至少一个)索引的网页数量就是 S=s(A)+s(B)-s(A&B);这个公式还可以推广到多个搜索引擎的情况,则此时S会越来越靠近真实的 Web 的规模。不过很遗憾,这个公式很不实用:-( 虽然 Google 不久前迫于 Cuil 的压力公布了自己的索引量,但其他几大搜索引擎仍习惯于对这个数据秘而不宣;更糟的是,Google 或是 Yahoo! 显然不可能把自己的索引库共享给对手以求得 s(A&B) 这项。不过,Bharat 和 Broder 在1998年基于统计学原理提出了一个很巧妙并且很著名的解决方法:记 Pr(A) 为某个元素属于集合 A 的概率,Pr(A&B|A) 为已知一个元素属于 A 时而它同时属于两个集合的条件概率。 则可以推出:Pr(A&B|A)≈s(A&B)/s(A),Pr(A&B|B)≈s(A&B)/s(B),即得 s(A)/s(B)≈Pr(A&B|B)/Pr(A&B|A)。而 Pr(A&B|B)、Pr(A&B|A) 都可以用随机采样的方法根据一系列精巧构造的搜索用例通过实际的搜索实验估计出来,从这两个值还可以用来估算出 s(A&B) 的大小。再进一步,从语言学模型中可以估计出之前构造的搜索用例在整个语言文本中出现的概率,从而估计出 s(A) 和 s(B) 具体的大小。
现在的问题就集中在3点:搜索用例的独立性、搜索用例的覆盖性、和结果检验的完整性(搜索结果集可能很大,如果只看靠前的部分,通常这部分的 rank 会比较高,因而被同时索引的概率也会偏高,参考下面的Web的结构一 节)。Bharat 和 Broder 构造的方法着重解决了前两个问题,他们报告当时(1997年底)的几大搜索引擎HotBot, AltaVista, Excite, Infoseek (其时 Google 还未正式发布) 的索引覆盖率 (占整个已被索引的 Web) 分别为:48%, 62%, 20%, 和 17%,而 Web 的总规模约为 220,000,000。值得注意的是,他们的结果还显示各引擎的重合率 (即 s(A&B)) 很低,平均只有 1.4%,可见当时的索引水平也还处于较低的阶段。到了 2005 年,Gulli 和 Signorini 改进了结果检验完整性的问题并在新的搜索巨头 Google, Yahoo!, Ask/Teoma, MSN 上进行了测试,结果它们各自的覆盖度分别为 76%, 69%, 58%, 62%,Web的总规模达到了约 11,500,000,000。2006 年 Bar-Yossef 和 Gurevich 进一步优化了随机采样的理论,根据他们的结果,当时 Google, Yahoo!, MSN 的覆盖率大约为:64%, 65%, 50%,重合率平均为 44%,比1997年有很大提高。他们并没有给出估计的Web总规模,不过这组覆盖率数值应该比较接近目前的水平,因此结合上面 Google 最新的索引数量,相信大家不难估计出当前 Web 的总规模。
上面讨论了Web的规模。我们知道,Web的特点是各个网页之间由超链接互相连接而形成的网状结构,那么这么大的一张网具有什么样的特点呢?
Andrei Broder等人在2000年比较早的研究了这个问题,他们的研究基于两个Web爬虫各自爬取的超过2亿个网页和15亿个超链接,他们认为这些网页具有一种类似“领结(bow tie)” 的结构。领结的形状大致是中间一个大的“结”以及两边各一个三角形的“花”,在每个“花”上面附着了一些穗状的“花边”,而两个花之间还有一条长的“项圈 ”让领结可以套在脖子上。中间的“结”是由约5600万网页组成的SCC(strong connected component,强连接组件),左边和右边的花分别是IN组件和OUT组件,分别包含4400万网页。剩下的4400万网页则是花上的穗状物 (TENDRIL组件)。在SCC组件中,任意两个网页都可以通过很短的有向链接路径到达彼此,它们是整个Web的核心部分。IN组件里的网页可以链入 SCC,但无法从SCC链回来,这些一般是比较新的网页还没有被大家所发现并链接到。OUT组件则是可以从SCC链入但不包含链回SCC的链接,这些可能 是一些只包含内部链接的企业网站。TENDRIL组件则是和IN或OUT组件相连但并不和SCC组件有较直接联系的网页,有趣的是,TENDRIL组件中 的一小部分可以联系IN和OUT组件而形成的“项圈”部分。还有很少一部分的网页是不被链接到的,不属于以上任何一个组件。这项结果中最令人惊奇的部分是 它显示SCC部分(整个 Web 中相互链接最稠密的部分,因而通常也是最经常浏览的部分,参考 PageRank 的基本原理,它们通常具有较高的 rank 值)的大小只占整个 Web 的一小部分,这暗示Web上可能大量充斥的是那些没多少“价值”的网页。
当然上面的是2000年的情况,在最近几年中Web的结构可能发生了变化,因此一些新的理论也被提了出来。2005年 Debora Donato 等人研究后认为,Web的结构已逐渐转变成一个类似“菊花” 的形状:在 IN 和 OUT 组件内部出现了很多符合 IN-OUT-SCC 关系的细微结构,因而 IN 和 OUT 可以进一步被细分而形成围绕在 SCC “花心”周围一圈大小不一的“花瓣”。不过在他们的结果中,SCC 的比例有所扩大,在部分数据集上甚至达到了 72.3%,这也让后来的研究者对他们的数据集覆盖性产生了一些怀疑,或许有一些较深的弱链接网页没有被他们索引到。另外,他们的结果还显示,不同语言的 Web 子集其结构有相当大的区别,其中最突出的特点是英语的页面无疑是 Web 的核心,其他语言的网页有很多指向英语网页的链接,而反过来的情况则相当的少。最后是中文 Web 的情况,今年 Jonathan J. H. Zhu 等的分析将中文 Web 形容为“茶壶”的结构:相比 IN 组件,OUT 组件的变小了很多,因而在 SCC 两侧构成了一大一小形如“把手”和“壶嘴”的结构,而游离的 TENDRIL 组件则很像壶中滴下的水滴。
本文固定链接: http://www.nuniao.com/on-the-web-you-may-not-know.html | 驽鸟公寓
关于Web,你可能不知道的……:目前有1 条评论
报歉!评论已关闭。
博客公告

最新评论
8853801@qq.com:
nuniao.net你收不收Always.Life:
严格遵守国家规定影乐:
还是没有解决...PC丶爱好者:
装了win8C盘就剩下800M了爱十佳:
坑爹假!趣你的:
现在xbox one很火!椒盐虾:
这个笑话有点长!watercity:
微软现在想搞硬件,怎么看?
昨天win8正式的刚出来,可以加百变贝贝::
可以把windows8 加上了
还真没关注这么多…
2008-09-18 3:06 下午